
谁是AI化学家?深势开源RxnBench,用Nature真题“考问”大模型推理极限
直面文献“深水区”,大模型离 AI 化学家还有多远?
当科研人员在浩如烟海的文献中寻觅合成灵感时,大模型能否真正成为具备深度化学素养的“AI 化学家”?
近日,由深势科技(DP Technology)主导并发布的开源多模态基准 RxnBench,致力于对当前大语言模型在真实科学文献中理解与解析化学反应的能力进行系统性、分层次评估。
RxnBench 的出现,在构建真正可靠、可推理的“AI 化学家”道路上,迈出了关键一步。

论文标题:
RxnBench: A Multimodal Benchmark for Evaluating Large Language Models on Chemical Reaction Understanding from Scientific Literature
论文地址:
https://arxiv.org/abs/2512.23565
GitHub地址:
https://github.com/uni-parser/RxnBench
数据集地址:
https://huggingface.co/datasets/UniParser/RxnBench
大模型在读懂涉及化学反应文献面临的挑战
在人工智能与化学的交叉领域,我们正处在一个微妙而关键的发展阶段。
尽管大模型在处理线性文本表示(如 SMILES 字符串)时表现优异,但面对蕴藏化学知识的真正宝库——学术论文PDF时,它们往往显得捉襟见肘。
化学知识高度浓缩于反应流程图、机理示意图和实验数据表中,理解这些内容需要深度的视觉与语言信息融合。
为何理解包含化学反应的文献对大模型如此困难?
2. 非结构化的 PDF 格式:PDF 本质上是为人类视觉阅读设计的格式。复杂的版面布局与跨页引用,使得模型在对齐化学信息时面临巨大困难。
3. 强依赖多模态推理:要回答诸如特定产物的产率与选择性问题,模型往往需要同时整合正文描述、图表编号及表格中的具体数据。
4. 近乎严苛的精度要求:在化学领域,一个手性中心的误判或反应条件的细微偏差,便可能导致完全错误的结论。
面对上述客观存在的挑战,深势科技设计并发布了 RxnBench——这是首个专门用于评估多模态大模型直接从真实文献中理解化学反应能力的综合性基准测试。RxnBench 的推出,填补了化学文献大模型评估领域的一项关键空白。
RxnBench 的双层评估架构
为保证基准的权威性与实际相关性,RxnBench 所有反应图示与 PDF 文献均提取自过去五年内发表于 Nature Chemistry、JACS 等化学顶尖期刊的高影响力开放获取论文。
为精准诊断大模型在化学文献理解中的能力“短板”,RxnBench 构建了一套双层评估体系:
1. 单图问答 (SF-QA)
SF-QA 聚焦于模型对单张反应图示的细粒度视觉感知与解析。在 SF-QA 建立中,利用深势科技自研的 PDF 文献解析框架 Uni-Parser 自动检测并裁剪反应图式,同时保留标题和标签等上下文信息,得到 305 张有机反应图示,并以此设计 1525 个 QA 对。
题目以四选一的选择题形式呈现,系统评估模型在有限图像上下文中的信息抓取与理解能力。
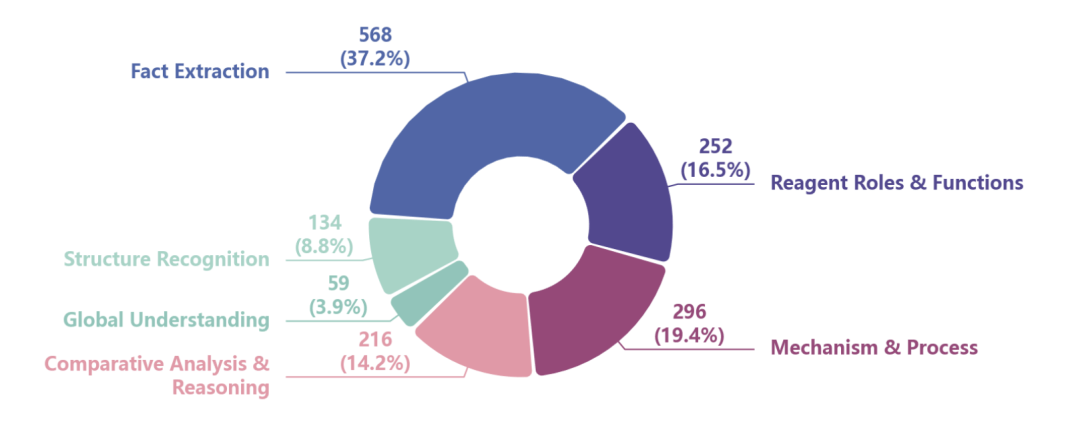
〓图1. SF-QA数据集中问题类型的分布
2. 全文问答 (FD-QA)
FD-QA 涵盖 108 篇有机化学 OA 文献,并模拟化学研究人员处理文献的真实工作流:通读整篇 PDF 并融合多位置信息进行综合推理。
为抑制模型“幻觉”与盲目猜测,本部分引入更严格的评估机制:
文档级整合:问题需模型综合正文叙述、反应图示及实验表格等多处信息,在全文语境中完成推理。
不定项选择:每题设 A–D 四个选项,可多选、单选或不选(无正确选项),以有效惩罚虚构答案,迫使模型进行事实核查。
多模态选项设计:答案形式涵盖纯文本、分子结构图像及文图混合布局,全面检验模型的视觉‑语言对齐与跨模态推理能力。

〓图2. (a) 用于单图问答构建的专家驱动注释流程,展示了问题生成和对抗性编辑的人工循环过程。(b) 全文问答设计原则,突出强调了强制严格评估的关键特征。
RxnBench 的评估结果
单图问答性能


SF-QA 评估结果显示,Gemini 系列模型目前在基准中表现最佳,其中 Gemini-3-Flash-preview 以 96.23% 的平均准确率位居前列。
与此同时,我们也观察到几个关键趋势:
推理能力带来显著提升:具备显式推理机制的模型表现明显优于仅经过指令微调的对应版本。
例如,Qwen3-VL-235B-A22B-Think 在 SF-QA 中达到 91.77% 的准确率,而其 Instruct 版本仅为 85.84%,显示通过增强推理可有效缩小与闭源模型之间的差距。
即使是表现领先的 Gemini-3-Pro-preview,在该类任务中也仅获得 74.63% 的准确率,这表明当前大模型在精细分子结构的视觉编码与理解方面仍存在本质性挑战。
全文问答性能

FD-QA 基准的测试难度明显更高,目前尚未有模型达到 50% 的准确率,这也凸显了从完整科学文献中进行信息综合所面临的内在挑战。
FD-QA 的评估结果进一步凸显了“思考型”模型的关键价值:缺乏显式推理机制的模型准确率普遍低于 20%。
相比之下,具备思维链(Chain-of-Thought)推理能力的模型表现显著更优,特别是 Gemini 系列模型,在该任务上取得了接近 46% 的准确率,说明结构化推理流程对复杂文档的理解与整合具有至关重要的作用。
此外,所有被测模型均呈现出一个共同趋势:在上下文推理(整合文本与表格信息)任务上的表现普遍优于结构推理(基于分子结构进行逻辑推导)。
例如,Gemini-2.5-Pro 在上下文推理任务上得分为 56.82%,而在结构推理任务上仅为 36.52%。这一差距反映出,当前的多模态大语言模型虽然能够较好地关联文本信息,但在结合文档中的视觉化学结构进行精确逻辑推导时,仍面临显著困难。
值得关注的是,评估中还出现了一个有趣现象:后发布的 Gemini-3-Flash-preview 在部分任务上甚至表现优于更早推出、成本更高的 Gemini-3-Pro-preview。
类似趋势也在其他多个 STEM 领域的基准测试中被观察到,暗示在特定任务场景下,模型并非总在规模或参数上“越大越优”,推理效率与架构设计同样影响最终性能。

〓图3. 基准模型和具有推理能力模型在全文问答上的性能差异
RxnBench 带来的启示和意义
RxnBench 的研究成果清晰揭示了当前多模态大语言模型在化学合成领域的能力水平与发展方向。
目前,先进模型已能较为可靠地从反应图示中提取明确信息,并对化学过程进行基础的文本推理。
RxnBench 的重要意义在于,它将大模型能力评估的范畴从简单的模式匹配,推进到了真正的科学认知层面。在科研日益向自主化、智能化发展的今天,这种能系统性评估模型对复杂、多模态科学信息进行可靠解释的基准,将成为确保大模型在未来实际科研中发挥关键作用的基石。
Light Chasers 招募
我们正在招募参与 AI for Science 长期实践的 Light Chasers。
我们正在推动 Agentic Science at Scale 的新实践:当科学问题的边界不断拓展、个人与工具之间的限制逐步消解时,那些同时具备好奇心、判断力与行动力的人,开始拥有更大的创造空间能够把探索做深、做实,并持续向前推进,而不再受制于零散条件与偶发路径。
这种实践不只是 AI for Science,也是 Science for Al:科学式的约束、验证与执行闭环,正在把智能从"会拟合、会生成",推向目标驱动、可验证、可演进的能力形态。