
震撼!2025 高考数学难吗,七家大模型应战,DeepSeek、讯飞星火竟率先破 140!
开心田螺
2025-06-09 10:59:49
0次
2025 年,七家主流大模型也加入了高考这场没有硝烟的 “战争”,本以为会是一场势均力敌的较量,却没想到 DeepSeek 和讯飞星火竟一骑绝尘,率先突破 140 分,让其他模型望尘莫及!

2025 年高考数学刚刚落下帷幕,关于试卷难度的讨论在网络上热度爆棚。而一场特别的 “考试” 也随之展开,七位 AI 大模型 “考生” 受邀参与,它们分别是 DeepSeek R10528、通义千问 Qwen3 - 235B - A22B、讯飞星火 X1 - 0420、豆包 Seed - Thinking - v1.5、文心 X1 Turbo、腾讯混元 Hunyuan T1 latest 以及 GPT o3。
为确保本次 “考试” 评测的准确性,不仅采用了多版本交叉验证,还邀请了拥有十年高中数学教研经验的专家汪鹏老师负责评分。
考试开始,在基础的选择题部分,各模型都表现不错,均顺利答对。然而,随着题目难度上升,差异逐渐显现。在涉及对数函数的选择题中,DeepSeek 和豆包出现了错误。

在解答题第 16 题中,DeepSeek、通义千问、讯飞星火和豆包表现优异,展示了清晰的解题过程,获得满分,而文心 X1 和腾讯混元则出现了不同程度的错误。
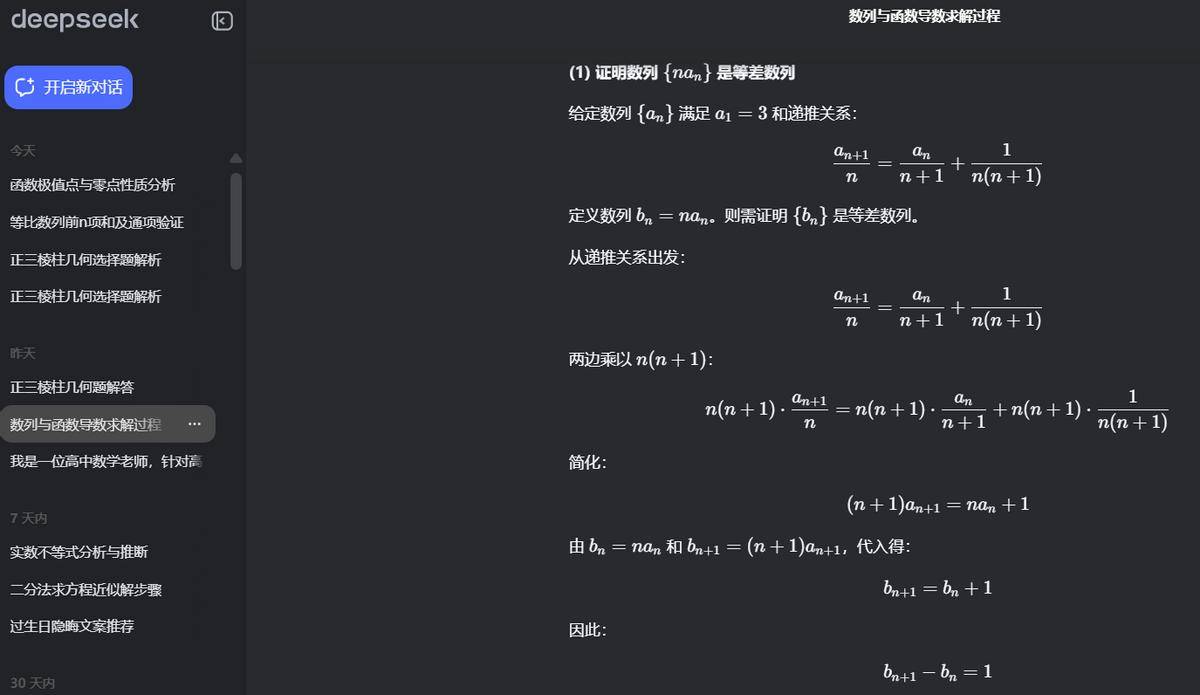
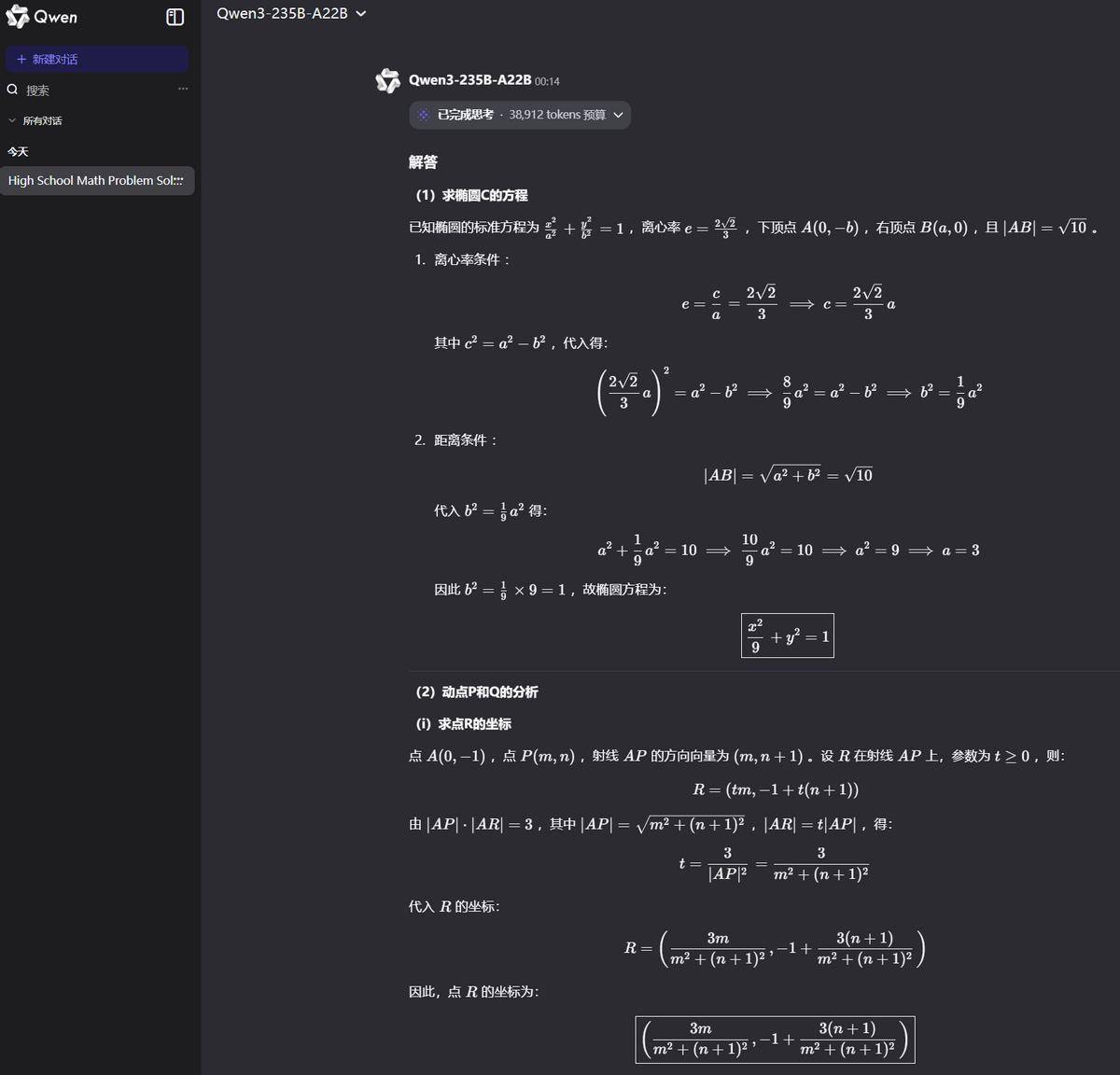
难度更高的第 18 题,讯飞星火、豆包、DeepSeek、通义千问和 GPT o3 获得满分,文心 X1 因答案错误失分。
最终成绩揭晓,DeepSeek 以 143 分的成绩勇夺榜首,讯飞星火以 141 分紧随其后,GPT o3 以 138 分位居第三。这场大模型的 “高考数学之战”,让我们看到了 AI 在数学领域的强大实力与无限潜力。
那么问题来了,随着 AI 技术不断发展,未来它们能否在教育领域彻底颠覆传统教学模式呢?让我们拭目以待。
相关内容
热门资讯
2026湘教版高中地理选择性必...
为了让大家做好课前预习和巩固复习,下面为大家准备了2026湘教版高中地理选择性必修二电子课本(高清版...
【40套】剑桥英语FCE考试官...
【40套】剑桥英语FCE考试官方真题10本PDF(青少版+标准版)含PDF+听力音频MP3,备考FC...
《中国青年报》|从课堂走向田野...
教育的生命力,在于理论与实践的深度融合。2025 年 3 月,中国政法大学与海淀区携手启动 “法治海...
京蒙教育协作 | 我区40余名...
为深化京蒙教育协作内涵,践行“融铸”式教育理念,铸牢中华民族共同体意识,2月1日到2月7日,内蒙古自...
通榆成人高考本科函授站
通榆成人高考本科函授站助力梦想起航的温馨港湾 在辽阔的东北平原上,有一片充满希望的土地,那就是通榆。...
中国军网点名张本智和!参拜东乡...
大家好呀!今天小妹儿带大家直击最新八卦! 2月9日,一条名为“中国军网点名张本智和”的词条成为了社交...
高效复盘,精准发力——山东潍坊...
艺考生文化课冲刺阶段,“只顾向前学、不顾回头看”是多数考生的通病,不少考生埋头刷题、拼命赶进度,却从...
新春走基层丨至少97次被拍下!...
2026新春走基层 | 盲人大学生记录春运回家路上的“温暖接力”,网友直呼“看哭了” “看(听)了评...
校友会2026台州市大学排名,...
1月12日,全国第三方大学评价机构艾瑞深校友会网(Cuaa.net)正式发布校友会2026中国大学排...
重庆大学师生来聊开展“高校师生...
鲁网2月9日讯2月1日至4日,重庆大学师生代表一行13人来聊开展“高校师生聊城行”活动,了解城市概况...