
LLM抢人血案:强化学习天才被挖空,一朝沦为「无人区」!

新智元报道
编辑:KingHZ
【新智元导读】AlphaStar等证明强化学习在游戏等复杂任务上,表现出色,远超职业选手!那强化学习怎么突然就不行了呢?强化学习到底是怎么走上歧路的?
最近,斯坦福的AI+CS博士Joseph Suarez发表了对强化学习的历史回顾。
结果,在𝕏上火了!目前,已有38.2万阅读。
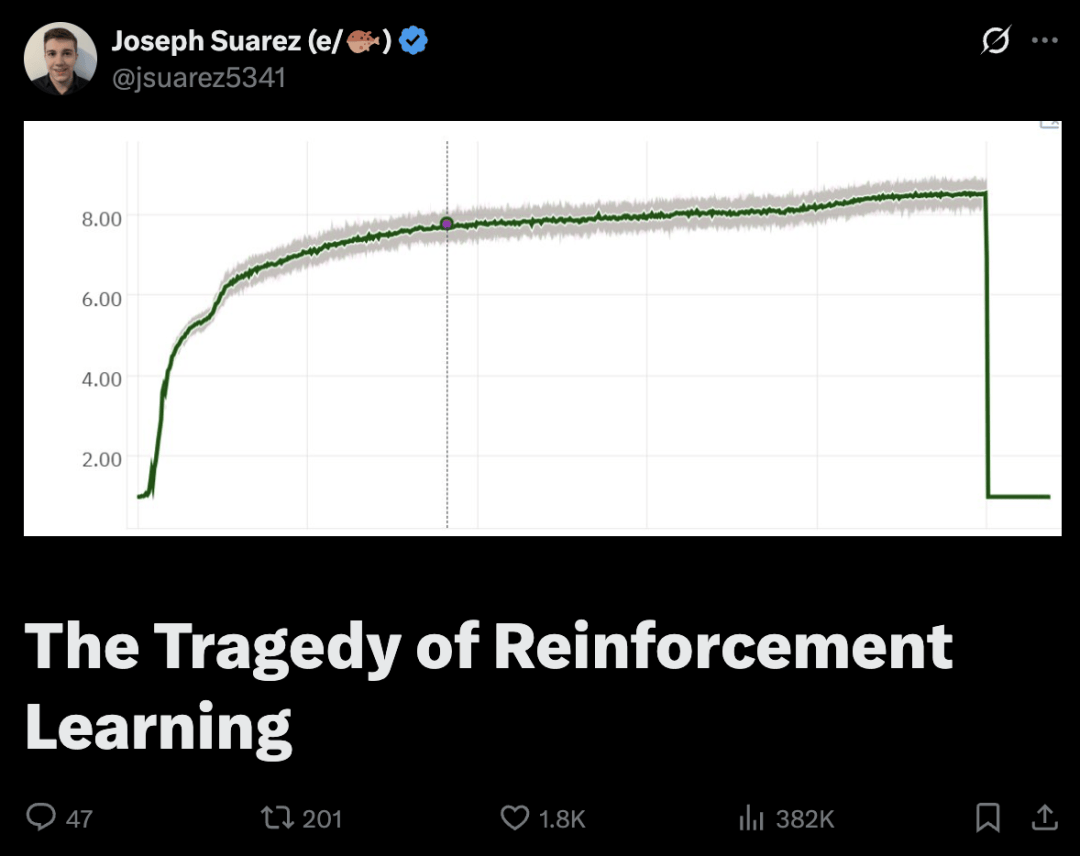
封面可谓醒目:一条曲线线先是快速上升,然后平缓爬升,最后却急转直下 ,暗喻RL领域的研究前途不妙!
从历史角度看,强化学习发生了什么?为什么到现在它才真正开始起飞?
他提供了独特的个人视角。

师出名门
2019年, 他本科毕业于斯坦福大学计算机科学专业人工智能方向。
2018年,他利用休学期在OpenAI完成6个月实习,期间正式发布Neural MMO首个公开版本
更早之前,他曾在李飞飞课题组、吴恩达实验室参与过研究项目。
大约从2017年,他开始从事强化学习。
当时,他在麻省理工学院Phillip Isola实验室攻读博士,开始创建开源计算研究平台Neural MMO。
他的研究聚焦于推动现代基于智能体的学习方法向更复杂、更具认知真实性的环境拓展。

后来,这个项目后来成为他整个博士生毕业论文的的主题。

论文链接:https://jsuarez5341.github.io/static/jsuarez_phd_thesis.pdf
这也为他PufferLib的工作奠定了基础。

当时,各大实验室也在做从零开始、非语言模型的强化学习RL。
事实上,这是当时大多数工作的重点:多智能体(multiagent)刚刚兴起,所有核心算法刚刚发布。
AlphaGo让研究者已经看到了强化学习的潜力。OpenAI Five正在开发中,当时他恰好在OpenAI实习,所以亲眼看到了一些工作。
OpenAI的DoTA(Dota 2)项目,则完全让他信服RL的神奇。

论文链接:https://cdn.openai.com/dota-2.pdf
你如果不玩这款游戏,难以想象这个问题有多复杂。
你不会相信人们居然把打DoTA当成爱好。它和围棋并非完全一样,无法直接比较,但它确实涉及许多围棋中没有的、与现实世界相关的推理类型。
比如,高低级策略、控制、团队协调和心智理论(theory of mind),这些只是其中几个例子。
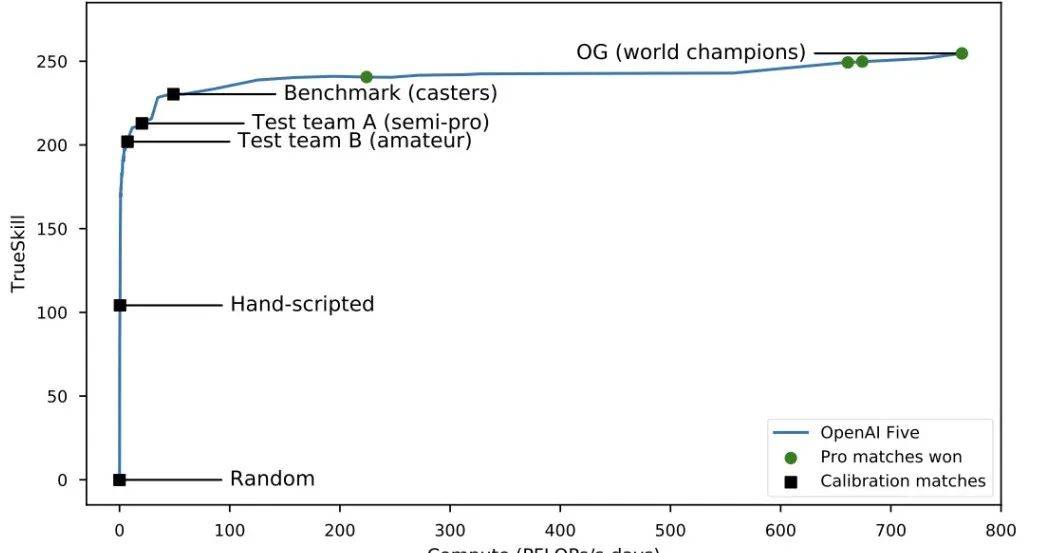
而OpenAI用1.68亿参数的网络,在约1000个GPU上训练,打败了顶尖职业选手。
现在,用64到128个H100 GPU,你也能做到。
而且还不止一个结果。还有AlphaStar、Capture the Flag、Emergent Tool Use……

在训练过程中,AlphaStar最终被选中与职业选手MaNa对抗的智能体(黑点)其策略与竞争对手(彩点)的演化过程。每个彩点代表AlphaStar联赛中的一位竞争对手
短短时间内,有好几个主要的RL展示项目。那么,既然潜力这么明显,领域肯定会继续前进,对吧……对吧???
为什么RL衰落了
从2019年到2022年的,有些工作继续在进行,但强化学习明显在走下坡路。
尽管那几年论文更多了,但没有多少像2017-2019年那种水平的持久突破。究竟发生了什么?
首要的因素是学术短视。
整个领域集体决定了一套标准,却没有实际理由。在这些标准下,几乎不可能出现什么进步。
由于历史原因,Agent57成为了最常见的基准,共包含57款雅达利游戏。

由于任务结果波动大,需要运行所有游戏(理想情况下,每款游戏使用多个种子)。同时,学界决定x轴应该是样本数,而不是实际运行时间(墙钟时间)。
背后的想法是,这更接近现实世界的学习,许多问题受限于采样率。而且你不用担心不同论文的硬件设置。
然而,显而易见的问题是没有限制硬件使用量,可以通过投入更多计算资源来提升基准成绩。因此,研究变得愈加耗时,以至于单个游戏的单独运行可能需要耗费数周的GPU时间。
因为学术界对工程很排斥,代码基底也慢得可怕。更不用说有限的预算……
所以,你最终需要1万GPU小时,在利用率不到5%的情况下运行一组消融实验(ablations)。
这样的研究方式根本行不通,跟好的科学更不沾边。
要是没有上万小时的GPU算力,很多人干脆不做消融实验就直接发论文——难怪那时候的研究成果基本无法复现。
另外,学界追名逐利。
大语言模型(LLMs)出现了。
人们经常问他为什么讨厌LLM。他真的不讨厌。他讨厌的是,它们从其他领域吸走了99%的天才,而不是更合理的80%。
他眼看着最有才华的同事一个个离开RL研究领域,被雇去研究LLM。这很难去责怪他们。做RL太糟了。那是艰苦、残酷的工作,对抗一套似乎专门设计来阻碍真正进步。
在一般深度学习中你习以为常的基本东西,甚至2015年的东西,在RL中都不存在。
超参数没道理,模型无法扩展,简单的任务也无法顺利转移。
尽管他们有证据证明RL能在DoTA和围棋之类的惊人问题上奏效,但日常工作的感觉就是绝望。
现在的RL重蹈覆辙
缓慢的实验周期、过度优化的评价体系、迟缓的开发进度……这一切听起来是否耳熟?
现代RL研究不知怎么花了数十亿美元,却再现了最初扼杀RL发展的混乱局面,重蹈覆辙。
David Peterson对此非常认同:强化学习莫名其妙地多次重蹈覆辙,上一次是时序差分。

这一次它会走得更远,毕竟有利可图……但效率极低。
看着该领域重新陷入前人多年前就已经克服的困境,同时为各种概念创造新的术语,令人啼笑皆非。
「多轮RL」意思是「不只是赌博机问题」(not a bandit)。这几乎涵盖了全部的RL新研究,除了某些小众理论研究。
「长期规划」(Long horizons)也不是新东西,这也不是让问题变得如此困难的全貌。
当前对早期RL研究的充满了不信任,Joseph Suarez表示理解——
因为许多发表的内容确实存在问题。
另寻他路
Joseph Suarez还在坚持用小模型从零开始的RL。
只是现在,这不再是衰落的旧势力,他们在以惊人速度突破。
那么,什么改变了?
完成博士学位后,他决定完全从学界的随意的标准中解放出来,从头重建RL。
标准是墙钟训练时间,性能工程将和算法工作一样重要。
他花几个月时间拆除所有慢的基础设施,目标是每秒数百万步的吞吐,而不是几千。
起初,这只是现有方法的加速版本。这对解决行业中因成本过高而难以实施的问题已绰绰有余。
但这还不止——这个过程实际上让他们能够以前所未有的速度开展高质量研究。当你可以运行1000倍的实验时,无需过于精巧的方法论;当所有选项都可以测试时,也无需小心翼翼地挑选变量。

最新基准测试显示,在单个RTX 5090上,强化学习库PufferLib 3.0的训练速度最高可达每秒400万步
一年前,你需要RL博士学位和几周到几个月来处理每个新问题。如果你没有经验,耗时就更长了。现在,新手程序员在几天内让RL在新问题上运行。不是超级难的问题——那些还是需要点经验。但比之前好多了。
他们走在正确方向的迹象:他们在简单环境上的实验能泛化到更难环境。
他们认为之前的batch size和特定退化超参数是罪魁祸首。不是100%——肯定有些技术只有在更难问题上才见效。
但他们现在有足够多在几分钟内运行的技术,开发周期还是很快。
下一步:他们计划能用现有东西解决有价值的问题。
只要能建快模拟器,RL大多能工作。嘿,在很多问题上,它开箱即用。
长期来看,他们会回到旧的样本效率研究。但他们还是会从至少保持flop效率的角度接近它。不再让GPU在5%利用率下跑批量大小8的200万参数网络。
参考资料: