
NOAI 2025 复赛真题(4道)
第1题:组合词分割

题目概述
组合词(Compounds)指的是由多个短词组成的新词,这在德语里尤为常见。例如:
• Fussball = Fuss(脚)+ Ball(球)
• Autobahnanschlussstelle(高速交叉路口)= Autobahn(高速公路)+ Anschluss(连接)+ Stelle(地点)
任务:将德语句子中的组合词分割成由空格分隔的短词。例如 "Fussballspieler" 应分割成 "Fuss"、"ball" 和 "spieler"。
数据集
• 训练集:94,306条德语组合词及其分割标签(train.json)
• 验证集:11,788条(val.json)
• 测试集:11,789条(test.json)
数据格式为JSON,key为组合词,value为0-1数组,1表示一个词的结束,0表示词的开始或中间。例如:
"Sprachbereich": [0,0,0,0,0,1,0,0,0,0,0,0,1] → 分割为 "Sprach" 和 "bereich"
约束条件
• GPU训练+测试时间不能超过10分钟
• 建议使用 Embedding + 深度学习模型
• 参考:Tesla T4 上 epoch 8~32 次可在10分钟内训练出较好结果
评分细节
F1-score = 2 × Precision × Recall / (Precision + Recall)。预测分词和真实分词在起始和结束位置完全一致才算正确(TP)。总分 = 所有样本F1得分的算术平均值。A榜为验证集得分(可查),B榜为测试集得分(赛后公布,作为最终成绩)。
第2题:化学反应动力学模拟

题目概述
一个典型的金属有机反应 L₂M + D ⇋ L₂MD 实际包含5个基元反应(含可逆和不可逆反应)。题目给出了所有5个基元反应的动力学方程以及描述8种物质浓度随时间变化的差分方程。
反应物的半衰期 t₁/₂ 定义为该反应物浓度减半所需的时间。本题使用 L₂M 的 t₁/₂ 来代表整体反应速率。
下图展示了不同初始条件下各物质浓度随时间的变化曲线:
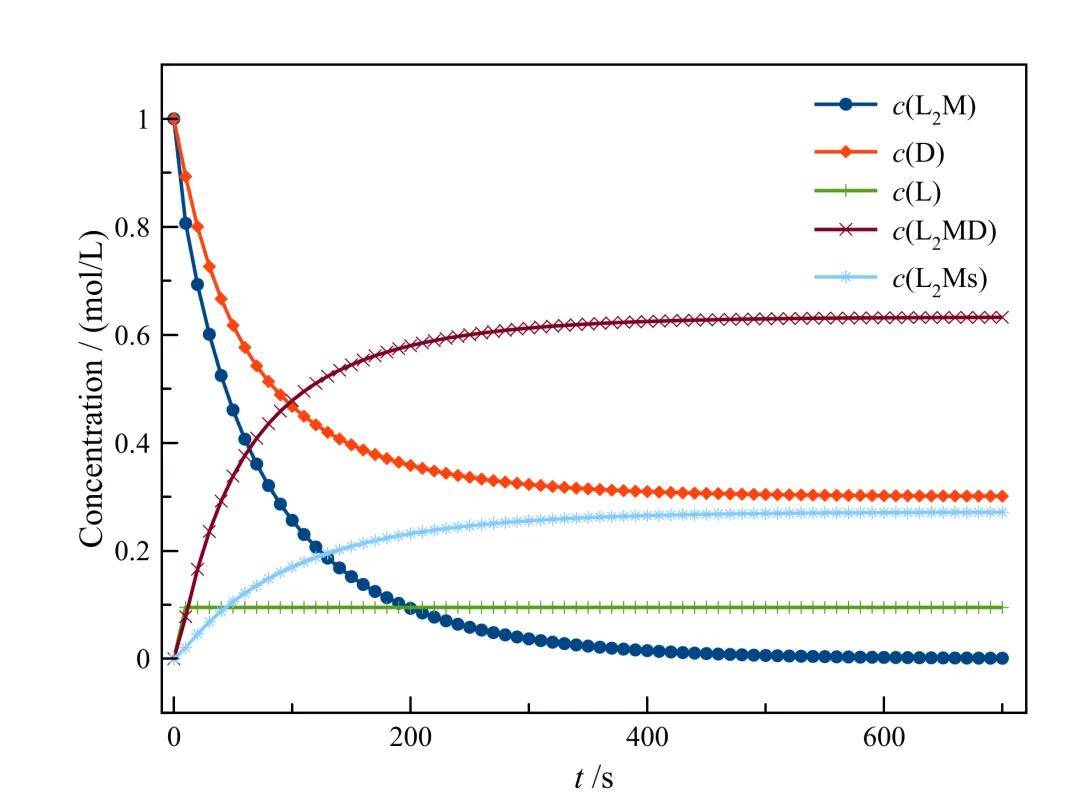
L初始浓度为0.0时的浓度-时间曲线
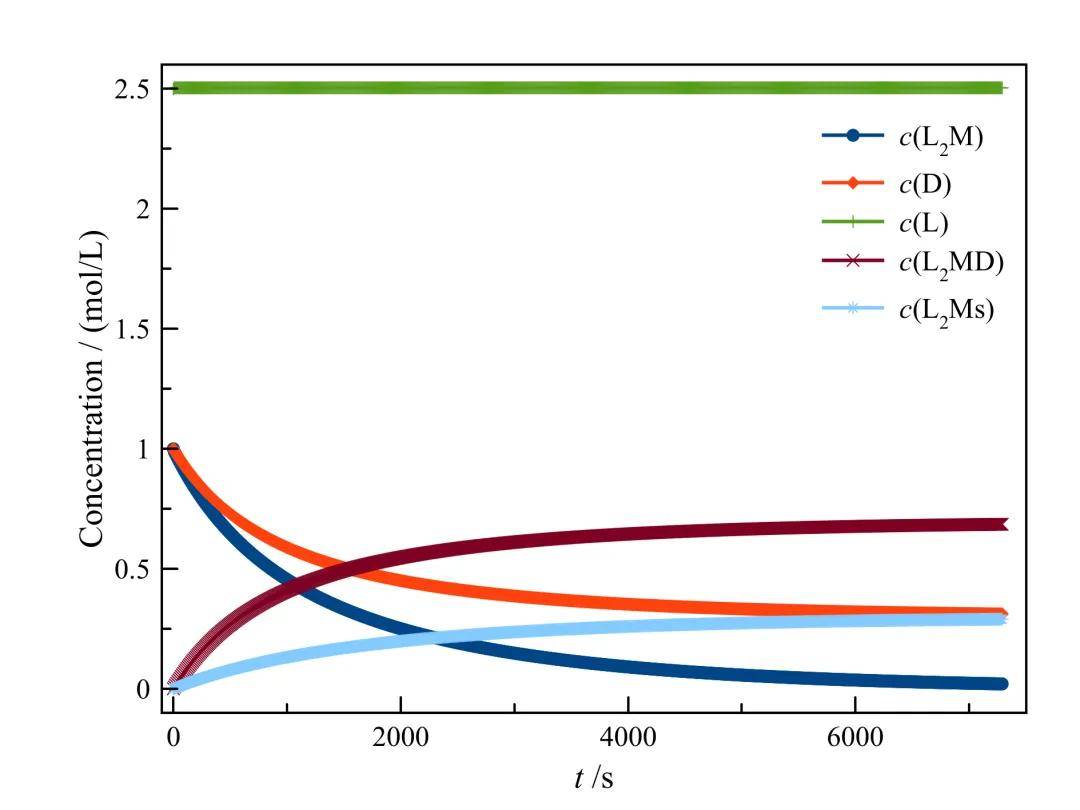
L初始浓度为2.5时的浓度-时间曲线
任务
根据每个实验中 c(L₂M)、c(D) 和 c(L) 的初始浓度,预测 L₂M 的半衰期 t₁/₂。
数据集
• 训练集:1000个独立实验的浓度-时间序列数据,每10秒记录一次
• 验证集(A榜):100个实验的初始浓度
• 测试集(B榜):412个实验的初始浓度
提示
对化学反应本身分析得越充分,求解越精确。参考方法:基于给出的浓度重新定义"Feature",再将Feature输入模型训练。由于Feature数比较少,不建议使用太复杂的模型。
评分公式
Score_i = max(0, 1 - ln(1 + 0.1 × |t₁/₂_predicted - t₁/₂_target|)⁵)
总分 = 所有实验 Score_i 的平均值。
第3题:合成语音检测

题目概述
使用 PyTorch 实现深度学习模型,从人类录音中检测合成语音。数据集收集于2019年。
原始音频已转化为梅尔频谱图(Mel Spectrum),以 .pt 格式存储。
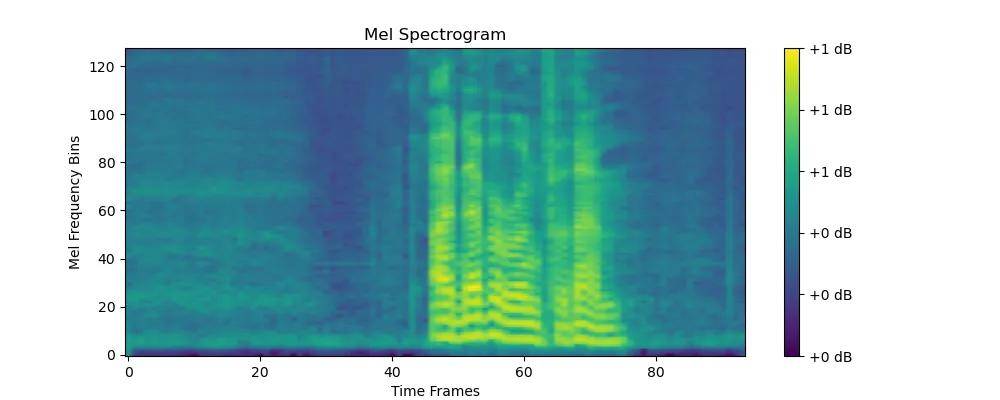
梅尔频谱图示例
技术细节
梅尔频率与真实频率的转换关系:m = 2595 × lg(1 + f/700)
转换参数:采样率 16000 Hz,梅尔滤波器数量 128,帧移 512,FFT窗口长度 1024。得到形状为 torch.Size([1, 128, 94]) 的张量。
数据集
• 训练集:bonafide(真实录音,标签0)和 spoof(合成语音,标签1)两个文件夹
• 验证集/测试集:只有频谱图,没有标签,通过加密环境变量访问
任务
建立一个能区分合成语音和真实录音的模型。可使用 resnet18 或其他 torchvision 模型进行 Fine-tune,也可以自己编写 CNN 模型。
提示
可以把这道题纯当做计算机视觉(CV)题目来做,不用纠结梅尔频谱图的物理实现过程。如果选择比 ResNet18 规模大的模型,需控制训练 epoch 数量。
第4题:宫格图分类

题目概述
设计并训练一个深度神经网络模型,判别输入图像是否为宫格图——一种将多张图片或同一张大图的不同区域通过创意拼贴组合成"格子"效果的图像形式。模型需要在多种拼接布局(规则网格、自由拼贴等)、不同分辨率与压缩质量环境下保持高精度与良好泛化能力。
(以下不是广告🤣)
正样本(宫格图)示例:




负样本(非宫格图)示例:




数据集
• 训练集:1000张图片,RGB,256×256,来自女装和美妆两个类目的商品展示图
• 验证集:100张
• 测试集:400张
关键陷阱
这是一道无监督学习题目。train.csv 中的类目标签区分的是"女装"还是"美妆",而不是"宫格图"还是"非宫格图"——相当于没有给任何有效标签。选手需要使用无监督学习方法让计算机自动区分宫格图;或者如果时间充足,手动打标签再训练也可以。
任务
使用 PyTorch 搭建模型,自由设计网络结构、损失函数和优化器,输出每张图片的预测标签(0=非宫格图,1=宫格图)。