
难受,字节到手的 offer 没了。。。
图解学习网站:
大家好,我是小林。
最近一段时间很多读者问我,他今年本科毕业,刚考完研,确认今年秋天去读硕士,相当于现在是硕 0,能否在暑假找个实习?
其实我觉得大概率是不可以的,主要是你现在的阶段,本科要毕业,然后硕士还没入职,其实在企业看来是应届生,实习一般是针对在校生的,虽然说你硕士即将入学,但是只要你还没入学,就还没拿到硕士生的身份。
而且即使有的企业能认可你硕 0 的身份,但是你最多只能实习 2-3 个月,这个实习时间有点太短了,一般企业都是期望实习生能实习半年以上的,所以从这个角度来看,这个硕 0 这个阶段是比较难拿到实习机会的,当然如果你家里人有人开公司,那估计还是有机会去实习的。
最近就在牛客网看到一个硕 0 找工作的案例,他字节面试全部通过了,也发了入职邮件,但是最后又不给发 offer 了,原因就是他是硕 0,而字节招聘的是应届生,就是希望毕业入职的正式员工弄,最后发现同学后面要去读研,不太符合应届生的要求,到手的 offer 就直接没了。
也有很多去实习的同学问我,在实习期间如何提高转正的概率,我这里给同学们几点意见作为参考:
首先肯定是要自己接到的需求,最好做好比较靠谱的感觉,就是不要闷头做事,啥也不交流,做好开发跟 leader 说一切没问题(原本有问题可能忘记上报憋着),结果上线出问题,这种给人的影响就不好了,因为你出事,背锅的也是领导,尽量站长领导角度思考,做的事情减少对他的影响,最好的效果是能“减负”他的工作,这样也会让他把比较重要的活慢慢给你,信任感其实就是通过工作中每一个小事情来积累起来的
除了好好完成自己手头上的工作,也要看看这个工作是否能超预期完成,比如领导可能只是让你实现这个,但是你发现实现这个基础上做了一些性能调优(当然前提是要把为什么可以调优,以及需要改动哪些,跟领导商讨之后在做),这样会给人的感觉你不会局限于完成工作,而是会主动思考的过程
工作除了开发之外,其实还一部分很重要的工作,就是维护系统和排斥 bug,这一块也可以多积极参与,其实也是积累对项目熟悉的一个方式,尽量也做到你负责的业务,出问题了,你能很快的定位出来,这样大家也会觉得你在这个业务上是最熟悉的那个人
之前也有研一同学在里认认真真踏实沉淀一年,最后研二的时候成功进入到字节跳动实习,有了这份实习的积累,不敢说在后面秋招能横着走,但是至少中大厂面试官看到有大厂实习经历,还是很愿意给面试机会的,甚至有可能拿到 sp、 ssp offer。
很多同学问过,大厂的一二三面有什么区别呀?
其实都是技术面,通常来说一二面会问比较多的技术问题,包括八股+项目+算法,大厂都会问到 1 个小时,基本上要扛住 30+ 个问题。
到了三面可能就有点不一样了,三面有时候就不会问太多八股了,因为一二面已经考察过了。
三面就更拷打你的项目,看你下做项目的思考能力,然后再问几个八股问题,通常就通过几个问题,看你对知识的深度,就不会像一二面那样,问你几十个技术八股问题。
今天就分享一位同学的字节三面的后端开发面经,除了拷打项目之外, 就问了几个八股,并且还没有手撕,半小时就结束了,三面结束,就到 hr 环节了。

字节三面什么字段适合当做主键?
字段具有唯一性,且不能为空的特性
字段最好的是有递增的趋势的,如果字段的值是随机无序的,可能会引发页分裂的问题,造型性能影响。
不建议用业务数据作为主键,比如会员卡号、订单号、学生号之类的,因为我们无法预测未来会不会因为业务需要,而出现业务字段重复或者重用的情况。
通常情况下会用自增字段来做主键,对于单机系统来说是没问题的。但是,如果有多台服务器,各自都可以录入数据,那就不一定适用了。因为如果每台机器各自产生的数据需要合并,就可能会出现主键重复的问题,这时候就需要考虑分布式 id 的方案了。
MySQL 的主从复制依赖于 binlog ,也就是记录 MySQL 上的所有变化并以二进制形式保存在磁盘上。复制的过程就是将 binlog 中的数据从主库传输到从库上。这个过程一般是异步的,也就是主库上执行事务操作的线程不会等待复制 binlog 的线程同步完成。
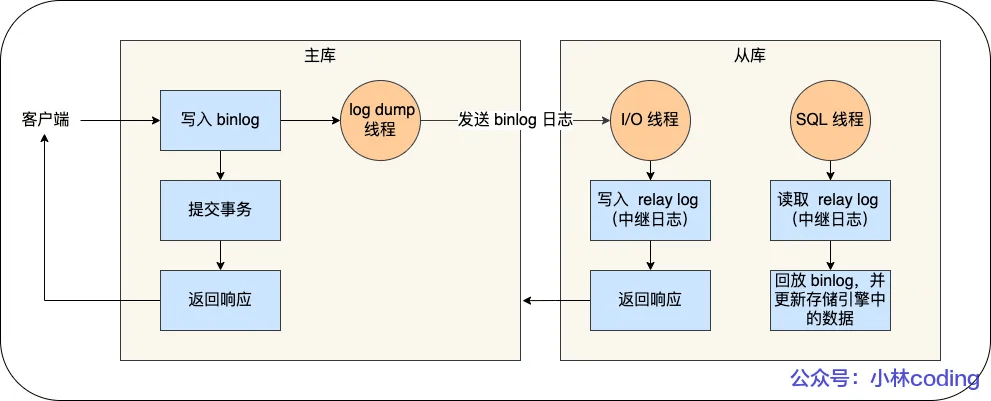
MySQL 集群的主从复制过程梳理成 3 个阶段:
写入 Binlog:主库写 binlog 日志,提交事务,并更新本地存储数据。
同步 Binlog:把 binlog 复制到所有从库上,每个从库把 binlog 写到暂存日志中。
回放 Binlog:回放 binlog,并更新存储引擎中的数据。
具体详细过程如下:
MySQL 主库在收到客户端提交事务的请求之后,会先写入 binlog,再提交事务,更新存储引擎中的数据,事务提交完成后,返回给客户端“操作成功”的响应。
从库会创建一个专门的 I/O 线程,连接主库的 log dump 线程,来接收主库的 binlog 日志,再把 binlog 信息写入 relay log 的中继日志里,再返回给主库“复制成功”的响应。
从库会创建一个用于回放 binlog 的线程,去读 relay log 中继日志,然后回放 binlog 更新存储引擎中的数据,最终实现主从的数据一致性。
在完成主从复制之后,你就可以在写数据时只写主库,在读数据时只读从库,这样即使写请求会锁表或者锁记录,也不会影响读请求的执行。
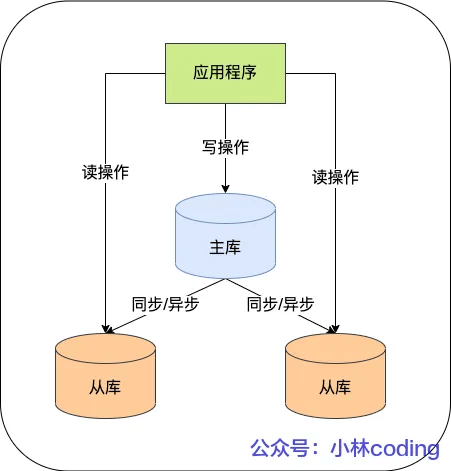
MySQL 主从复制还有哪些模型?
主要有三种:
同步复制:MySQL 主库提交事务的线程要等待所有从库的复制成功响应,才返回客户端结果。这种方式在实际项目中,基本上没法用,原因有两个:一是性能很差,因为要复制到所有节点才返回响应;二是可用性也很差,主库和所有从库任何一个数据库出问题,都会影响业务。
异步复制(默认模型):MySQL 主库提交事务的线程并不会等待 binlog 同步到各从库,就返回客户端结果。这种模式一旦主库宕机,数据就会发生丢失。
半同步复制:MySQL 5.7 版本之后增加的一种复制方式,介于两者之间,事务线程不用等待所有的从库复制成功响应,只要一部分复制成功响应回来就行,比如一主二从的集群,只要数据成功复制到任意一个从库上,主库的事务线程就可以返回给客户端。这种半同步复制的方式,兼顾了异步复制和同步复制的优点,即使出现主库宕机,至少还有一个从库有最新的数据,不存在数据丢失的风险。
MySQL 在完成一条更新操作后,Server 层还会生成一条 binlog,等之后事务提交的时候,会将该事物执行过程中产生的所有 binlog 统一写 入 binlog 文件,binlog 是 MySQL 的 Server 层实现的日志,所有存储引擎都可以使用。
binlog 是追加写,写满一个文件,就创建一个新的文件继续写,不会覆盖以前的日志,保存的是全量的日志,用于备份恢复、主从复制;
binlog 文件是记录了所有数据库表结构变更和表数据修改的日志,不会记录查询类的操作,比如 SELECT 和 SHOW 操作。
binlog 有 3 种格式类型,分别是 STATEMENT(默认格式)、ROW、 MIXED,区别如下:
STATEMENT:每一条修改数据的 SQL 都会被记录到 binlog 中(相当于记录了逻辑操作,所以针对这种格式, binlog 可以称为逻辑日志),主从复制中 slave 端再根据 SQL 语句重现。但 STATEMENT 有动态函数的问题,比如你用了 uuid 或者 now 这些函数,你在主库上执行的结果并不是你在从库执行的结果,这种随时在变的函数会导致复制的数据不一致;
ROW:记录行数据最终被修改成什么样了(这种格式的日志,就不能称为逻辑日志了),不会出现 STATEMENT 下动态函数的问题。但 ROW 的缺点是每行数据的变化结果都会被记录,比如执行批量 update 语句,更新多少行数据就会产生多少条记录,使 binlog 文件过大,而在 STATEMENT 格式下只会记录一个 update 语句而已;
MIXED:包含了 STATEMENT 和 ROW 模式,它会根据不同的情况自动使用 ROW 模式和 STATEMENT 模式;
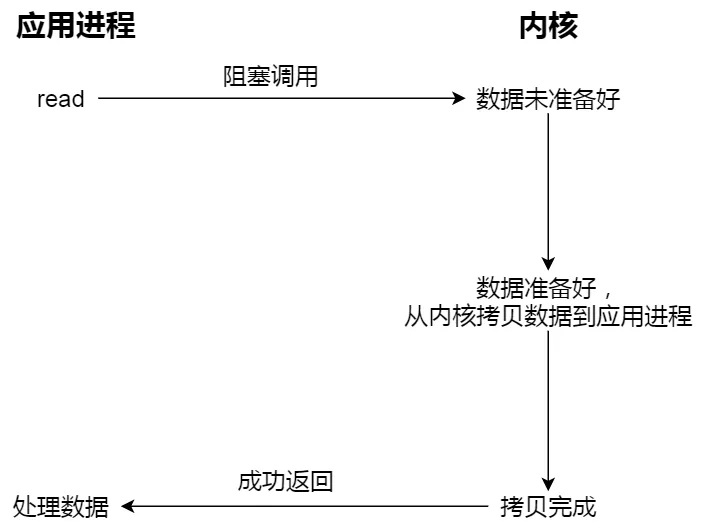
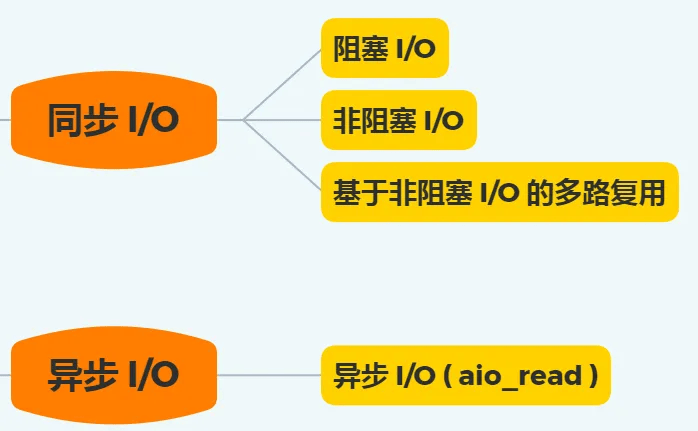
先来看看阻塞 I/O,当用户程序执行 read ,线程会被阻塞,一直等到内核数据准备好,并把数据从内核缓冲区拷贝到应用程序的缓冲区中,当拷贝过程完成,read 才会返回。注意,阻塞等待的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程。过程如下图:
知道了阻塞 I/O ,来看看非阻塞 I/O,非阻塞的 read 请求在数据未准备好的情况下立即返回,可以继续往下执行,此时应用程序不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区,read 调用才可以获取到结果。过程如下图:
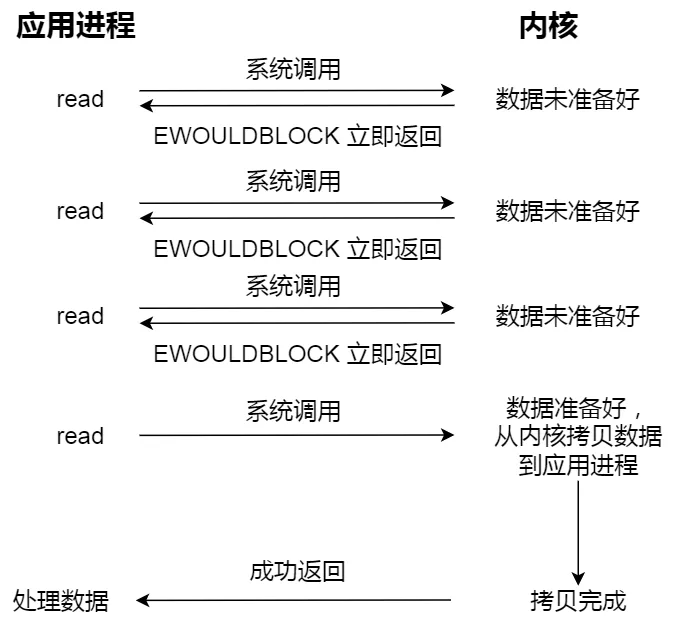
注意,这里最后一次 read 调用,获取数据的过程,是一个同步的过程,是需要等待的过程。这里的同步指的是内核态的数据拷贝到用户程序的缓存区这个过程。
举个例子,访问管道或 socket 时,如果设置了 O_NONBLOCK 标志,那么就表示使用的是非阻塞 I/O 的方式访问,而不做任何设置的话,默认是阻塞 I/O。
应用程序每次轮询内核的 I/O 是否准备好,感觉有点傻乎乎,因为轮询的过程中,应用程序啥也做不了,只是在循环。
为了解决这种傻乎乎轮询方式,于是 I/O 多路复用技术就出来了,如 select、poll,它是通过 I/O 事件分发,当内核数据准备好时,再以事件通知应用程序进行操作。
这个做法大大改善了 CPU 的利用率,因为当调用了 I/O 多路复用接口,如果没有事件发生,那么当前线程就会发生阻塞,这时 CPU 会切换其他线程执行任务,等内核发现有事件到来的时候,会唤醒阻塞在 I/O 多路复用接口的线程,然后用户可以进行后续的事件处理。
整个流程要比阻塞 IO 要复杂,似乎也更浪费性能。但 I/O 多路复用接口最大的优势在于,用户可以在一个线程内同时处理多个 socket 的 IO 请求。
用户可以注册多个 socket,然后不断地调用 I/O 多路复用接口读取被激活的 socket,即可达到在同一个线程内同时处理多个 IO 请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
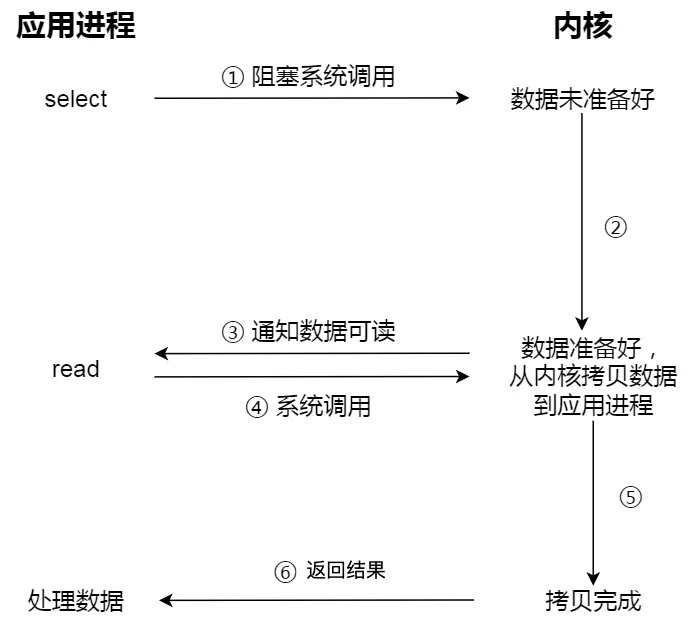
下图是使用 select I/O 多路复用过程。注意,read 获取数据的过程(数据从内核态拷贝到用户态的过程),也是一个同步的过程,需要等待:
实际上,无论是阻塞 I/O、非阻塞 I/O,还是基于非阻塞 I/O 的多路复用都是同步调用。因为它们在 read 调用时,内核将数据从内核空间拷贝到应用程序空间,过程都是需要等待的,也就是说这个过程是同步的,如果内核实现的拷贝效率不高,read 调用就会在这个同步过程中等待比较长的时间。
而真正的异步 I/O是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待。
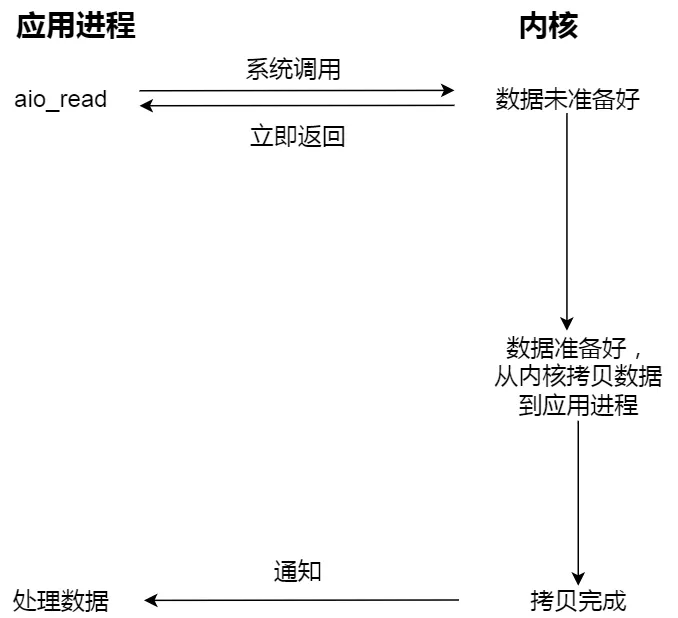
当我们发起 aio_read 之后,就立即返回,内核自动将数据从内核空间拷贝到应用程序空间,这个拷贝过程同样是异步的,内核自动完成的,和前面的同步操作不一样,应用程序并不需要主动发起拷贝动作。过程如下图:
下面这张图,总结了以上几种 I/O 模型:
在前面我们知道了,I/O 是分为两个过程的:
数据准备的过程
数据从内核空间拷贝到用户进程缓冲区的过程
阻塞 I/O 会阻塞在「过程 1 」和「过程 2」,而非阻塞 I/O 和基于非阻塞 I/O 的多路复用只会阻塞在「过程 2」,所以这三个都可以认为是同步 I/O。异步 I/O 则不同,「过程 1 」和「过程 2 」都不会阻塞。
用故事去理解这几种 I/O 模型
举个你去饭堂吃饭的例子,你好比用户程序,饭堂好比操作系统。
阻塞 I/O 好比,你去饭堂吃饭,但是饭堂的菜还没做好,然后你就一直在那里等啊等,等了好长一段时间终于等到饭堂阿姨把菜端了出来(数据准备的过程),但是你还得继续等阿姨把菜(内核空间)打到你的饭盒里(用户空间),经历完这两个过程,你才可以离开。
非阻塞 I/O 好比,你去了饭堂,问阿姨菜做好了没有,阿姨告诉你没,你就离开了,过几十分钟,你又来饭堂问阿姨,阿姨说做好了,于是阿姨帮你把菜打到你的饭盒里,这个过程你是得等待的。
基于非阻塞的 I/O 多路复用好比,你去饭堂吃饭,发现有一排窗口,饭堂阿姨告诉你这些窗口都还没做好菜,等做好了再通知你,于是等啊等(select 调用中),过了一会阿姨通知你菜做好了,但是不知道哪个窗口的菜做好了,你自己看吧。于是你只能一个一个窗口去确认,后面发现 5 号窗口菜做好了,于是你让 5 号窗口的阿姨帮你打菜到饭盒里,这个打菜的过程你是要等待的,虽然时间不长。打完菜后,你自然就可以离开了。
异步 I/O 好比,你让饭堂阿姨将菜做好并把菜打到饭盒里后,把饭盒送到你面前,整个过程你都不需要任何等待。
最近读了什么书?
根据自己的学习情况回答就行,主要看你学习的时候是否有看书,书的内容相对会比较体系一点,也能通过你现阶段看的书,大概了解你的学习情况。
算法
无手撕。。